PyTorch 101 - Part 1
Basics of pytorch
PyTorch 101 - Part 1
Overview
Why PyTorch?
- N-dimensional Tensor computation on GPUs
- Automatic differentiation for training deep neural networks
Training & Testing
Tools
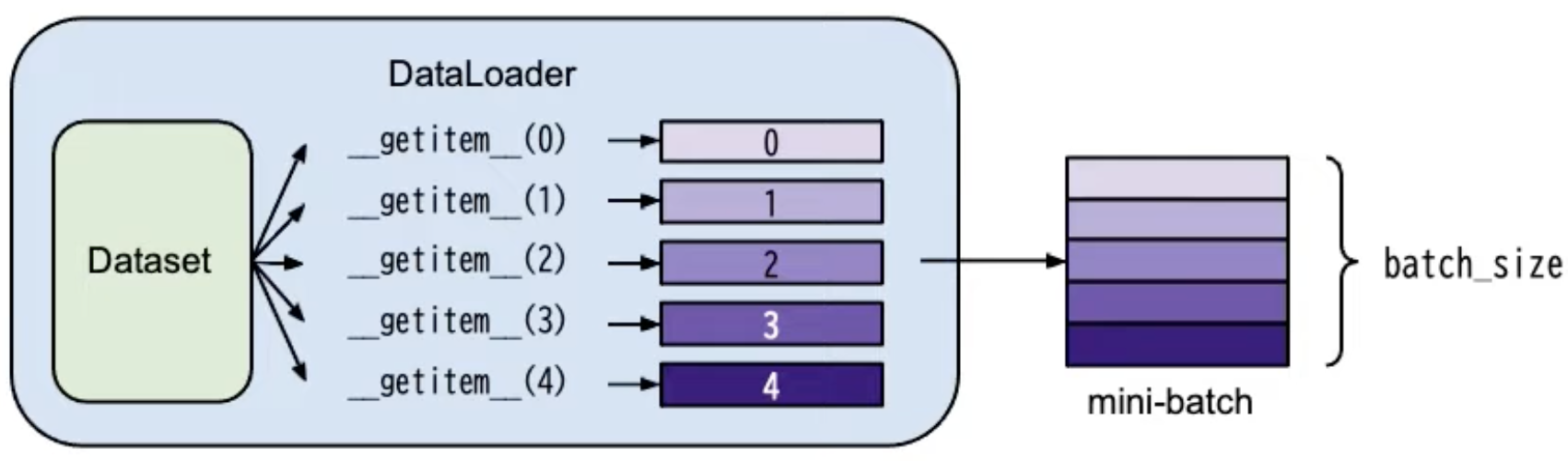
- torch.utils.data.Dataset: stores data samples and expected values
- torch.utils.data.DataLoader: groups data in batches
Usage
- dataset = MyDataset(file)
- dataloader = DataLoader(dataset, batch_size, suffle=True) // training: shuffle=True; Testing: suffle=False£¢¢4
MyDataset:
1 2 3 4 5 6 7
class MyDataset(dataset): def __init__(self, file): self.data = ... def __getitem__(self, index): return self.data[index] def __len__(self): return len(self.data)
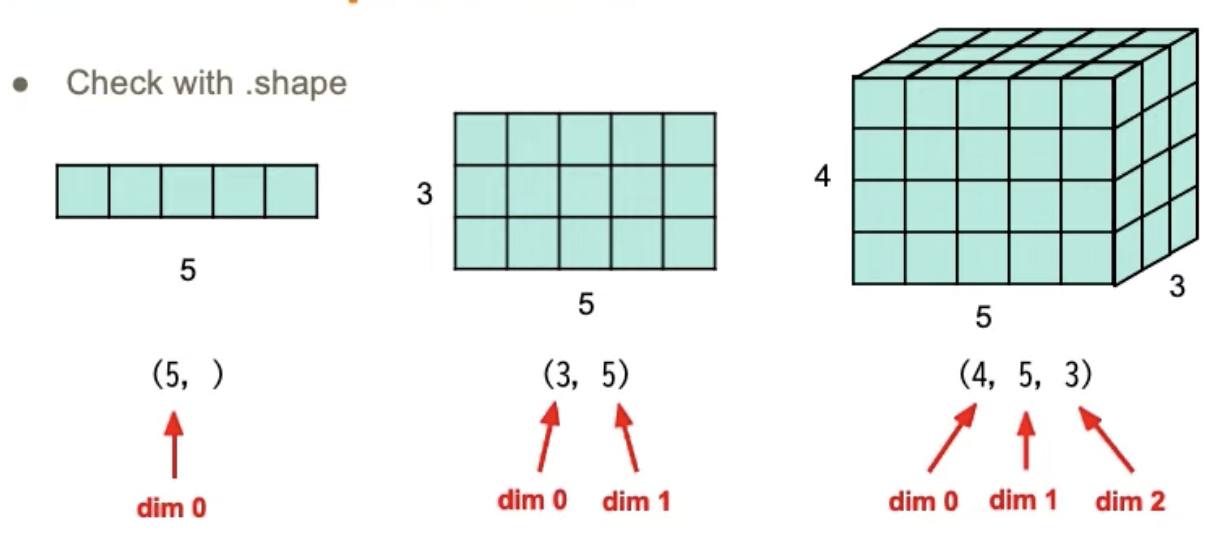
Tensor
high-dimensional matrices(or arrays)
Shape
Creation
- directly from data:
1 2
x = torch.tensor([[1,-1],[-1,1]]) x = torch.from_numpy(np.array())
- tensor of constant zeros/ones
1 2
x = torch.zeros([2,2]) # shapes, will create "tensor([[0., 0.], [0., 0.]])" x = torch.ones([1,2,5]) # likewise
Operation
- Addition
1
z = x + y
- Subtraction
1
z = x - y
- Power
1
y = x.pow(2)
- Summation
1
y = x.sum()
- Mean
1
y = x.mean()
- Transpose: transpose 2 specific dimensions
1
x = x.transpose(0,1) # select two dimensions and switch
- Squeeze: remove the specified dimension with length = 1
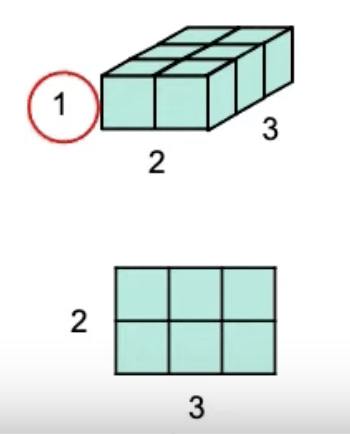
1 2 3
x = torch.zeros([1,2,3]) x = x.squeeze(0) x.shape # will be torch.Size([2,3])
- Unsqueeze: expand a new dimension
- Cat: concatenate multiple tensors
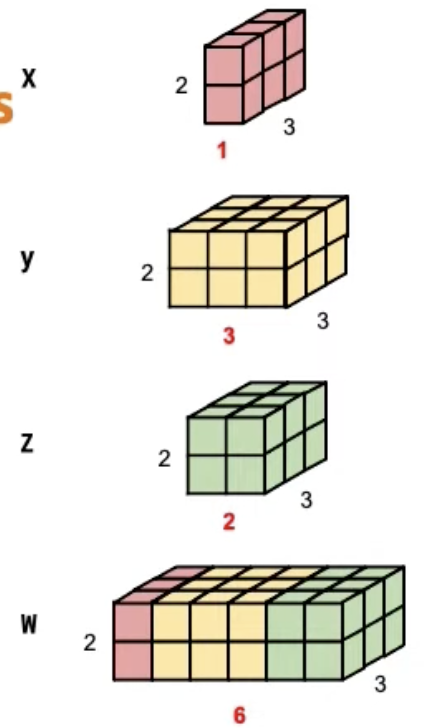
1
2
3
4
5
6
7
``` python
x = torch.zeros([2, 1, 3])
y = torch.zeros([2, 3, 3])
z = torch.zeros([2, 2, 3])
w = torch.cat([x,y,z], dim=1)
w.shape() # will be torch.Size([2,6,3])
```
Gradient Calc
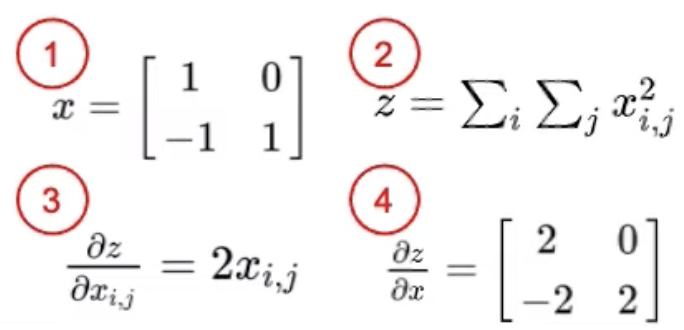
1
2
3
4
x = torch.tensor([[1.,0.],[-1.,1]], requires_grad=True)
z = x.pow(2).sum()
z.backward()
x.grad # tensor([[2.,0.][-2.,2.])
Neural Network
torch.nn - network layers
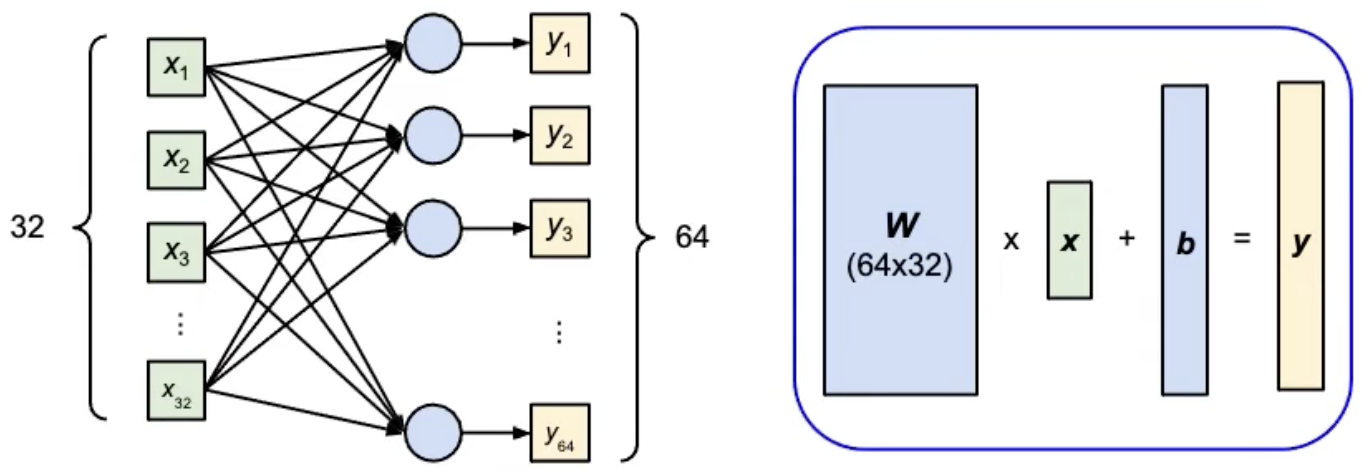
Example - Linear Layer
1
2
3
4
# nn.Linear(in_features, out_features)
layer = torch.nn.Linear(32,64)
layer.weight.shape # torch.Size([64,32])
layer.bias.shape # torch.Size([64])
Build a NN
1
2
3
4
5
6
7
8
9
10
11
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.net = nn.Sequential(
nn.Linear(10,32),
nn.Sigmoid(), # nn.ReLu()
nn.Linear(32,1)
)
def forward(self,x):
return self.net(x)
Loss Function
- Mean Squared Error(for regression tasks)
1
criterion = nn.MSELoss()
- Cross Entropy(for classification tasks)
1
criterion = nn.CrossEntropyLoss()
- loss = criterion(model_output, expected_value)
Optimizer
Gradient-based optimization algorithms that adjust network parameters to reduce error.
Implementation
- Call
optimizer.zero_grad()to reset gradients of model parameters - Call
loss.backward()to backpropagate gradients of prediction loss - Call
optimizer.step()to adjust model parameters
Neural Network Training Steps
a simple training procedure of a neural network using torch
Setting up
1
2
3
4
5
dataset = MyDataSet(file) # read data via MyDataSet as defined above
training_set = DataLoader(dataset, 16, shuffle=True) # put dataset into DataLoader
model = MyModel().to(device) # construct model and move to device(cpu/cuda)
criterion = nn.MSELoss() # set loss function
optimizer = torch.optim.SGD(model.parameters(), 0.1) # set optimizer
Training Loops
1
2
3
4
5
6
7
8
9
for epoch in range(n_epochs):
model.train() # set model to training mode
for x,y in training_set: # iterate through the DataLoader
optimizer.zero_grad()
x, y = x.to(device), y.to(device)
pred = model(x) # forward pass(compute output)
loss = criterion(pred, y)
loss.backward()
optimizer.step() # update model with optimizer
Validation Loops
1
2
3
4
5
6
7
8
9
model.eval() # set model to evaluation mode
total_loss = 0
for x,y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass
loss = criterion(pred, y)
total_loss += loss.cpu().item() * len(x)
avg_loss = total_loss / len(dv_set.dataset)
Testing Loops
1
2
3
4
5
6
7
model.eval()
preds = []
for x in tt_set:
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(ptrd.cpu()) # collect prediction
why
model.eval(): changes behaviour of some model layers, such as dropout and batch normalization
why
with torch.no_grad(): prevents calcilations from being added into gradient computation graph, usually used to prevent accidental training on validation/testing data
S/L Trained model
1
2
3
4
5
# saving
torch.save(model.state_dict(), path)
# loading
ckpt = torch.load(path)
model.load_state_dict(ckpt)
This post is licensed under CC BY 4.0 by the author.